
From restaurants (Yelp) to hotels (TripAdvisor) to books (Goodreads) to household goods (Amazon), the “ratings and reviews” model is everywhere. So much so that The Onion wrote a satiric article about a woman who dared to eat at a restaurant without reading the Yelp reviews.
But increasingly, the “ratings & reviews” model is perceived as broken and corrupt.
People believe reviews are manipulated on all fronts. They think businesses write bad reviews about their competitors. That businesses write good (but fake) reviews about their own businesses. That Yelp, for example, asks for money to suppress bad reviews (Yelp has been found not guilty in court). Businesses are at odds with customers over reviews: Fed-up restaurant owners fight back over Yelp reviews. Yelp, Amazon and TripAdvisor wage continual warfare over bad or fake reviews: Yelp Starts Showing Evidence Of Review Fraud.
There’s a lot of money at stake based on the outcome and incentives are skewed. This isn’t lost on consumers, who are increasingly cynical about the ratings and reviews they see online.
As a result, the “ratings & reviews” method of discovery and decision making is breaking down.
It’s not just restaurants and hotels. Closer to home for The Hawaii Project, the Books world has seen a number of scandals around purchased or fake book reviews, with a number of companies in the business of getting more reviews for a book (and they’re not going to be bad reviews!).
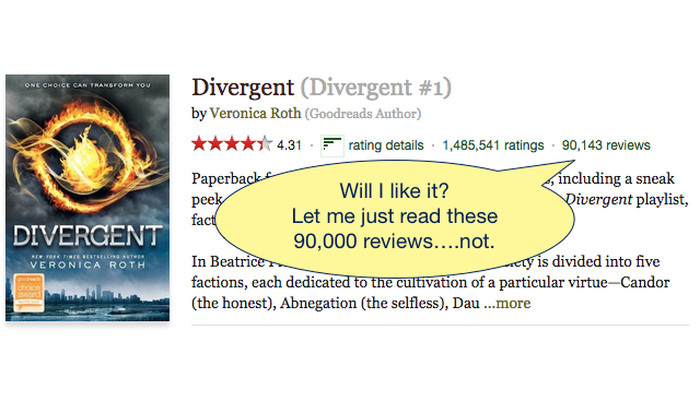
And even if the reviews aren’t fake, there’s an even deeper issue. They just aren’t that helpful in the end. Unless I have a relationship with the reviewer, I don’t know how to evaluate their review — do they share my tastes and values? No way to tell. They may not like something, not because it’s intrinsically bad, but just because it’s not for them (in the hotel space, studies have shown that most 1-star reviews are for bad service, but that most people value location and comfort much more than “service”). In the world of books, JoJo Moyes’ book Me Before You is rated 4.3/5.0 on Goodreads, with over 215,000 ratings and 30,000 reviews. Is it a good book? Probably so. Will I like it? Probably not. But I’m sure as hell not going to read 30,000 reviews to find out!
This isn’t helpful. The ratings and reviews decision-making model is busted. Too much noise, not enough signal. It’s time to replace it with something better.
In the music world, people often discover new music by listening to the curators.Pitchfork. Rolling Stone. The Radio. Your favorite DJ. Gramaphone Magazine.Apple’s new Beats music service leans hard on Curators. There are some great curators out there in other areas. Robert Scoble for Startups. Maria Popova for intellectual ideas and books. Jason Hirschhorn for Media. Even Kanye once called himself a curator! But who has time to keep up with all that?
The additional problem with books is that the curators’ tastes often don’t agree with your own, and the volume of books is so much larger. One minute The New York Times Review of Books is reviewing ‘‘Great Men Die Twice,’ a Collection of Sports Reporting by Mark Kram’, the next they are reviewing ‘Eye of the Beholder: Johannes Vermeer, Antoni van Leeuwenhoek, and the Reinvention of Seeing’ (a study of 17th century Dutch painting). Nothing whatsoever to do with each other, and neither interesting to me, personally. Imagine trying to figure out what to read by wading through all that!
Ratings and Reviews work when there is Trust and Context. Consumer Reports is useful because I trust them to be unbiased. My friend’s review of a restaurant works, not necessarily because I share their taste, but rather I have context for their opinion. I know them and how they think and what they like. On most major review sites in any domain, either Trust or Context (or both) are missing.
There’s a better way. I call it Personalized Curation.
Imagine if every day you had time to read what all the great curators and reviewers were recommending in your areas of interest, skipping the irrelevant things and highlighting the most personally interesting to you.
Systems that perform this “Personalized Curation” for you will become the norm over the next few years. People don’t have time to ready everything — there’s an explosion of content out there. You need some kind of agent who can assimilate all of that, and bring you the relevant bits. Because of the complexity of the problem, these agents will be domain specific. Music. Books. Movies. News. Hotels. And they will be contextual and pro-active. They’ll know you’re at the airport and need a great book for the flight, and bring it to you. They’ll know your wife’s birthday is coming up and bring you some great restaurant ideas.
This is beginning to happen. You can see the beginnings of it in music with Apple Beats and Shuffler.FM. Flipboard has been nosing around this for News for some time. And at The Hawaii Project, we’re doing it for books. If you’re looking for great books read, give us a whirl!

The Hawaii Project

{kind=link}